
فایل robots.txt (فایل روبوت) مجموعه ای از دستورالعملها برای رباتها است. این فایل در فایلهای منبع اکثر وبسایتها قرار دارد.
فایلهای Robots.txt (فایل روبوتس) بیشتر برای مدیریت فعالیتهای رباتهای خوب مانند خزندههای وب در نظر گرفته شدهاند، زیرا رباتهای بد احتمالاً دستورالعملها را دنبال نمیکنند.
Robots.txt یک فایل متنی است که مدیران وبسایت برای آموزش به رباتهای وب (معمولاً روباتهای موتورهای جستجو) ایجاد میکنند که چگونه صفحات را در وبسایت خود بخزند.
پروتکل حذف ربات که بیشتر با نام robots.txt شناخته میشود، درواقع قراردادی برای جلوگیری از دسترسی خزندههای وب به تمام یا بخشی از یک وبسایت است.
این فایل متنی برای سئو و بهینه سازی سایت استفاده میشود و حاوی دستوراتی برای رباتهای نمایهساز موتورهای جستجو است که صفحاتی را مشخص میکند که هم امکان ایندکس شدن دارند و هم ندارند.
یک فایل robots.txt را مانند یک علامت در نظر بگیرید که روی دیوار یک باشگاه ورزشی، یک کافیشاپ یا یک مرکز خرید نصب شده است، این علامت بهخودیخود قدرتی برای اجرای قوانین ذکر شده ندارد، اما مانند مشتریانی خوب هستند که قوانین را رعایت خواهند کرد.
robot یک برنامه کامپیوتری خودکار است که با وبسایتها و برنامهها تعامل دارد. رباتهای خوب و رباتهای بد وجود دارند و یک نوع ربات خوب، ربات خزنده وب نامیده میشود.
این رباتها صفحات وب را میخزند و محتوا را فهرستبندی میکنند تا بتواند در نتایج موتورهای جستجو نشان داده شود.
فایل robots.txt بخشی از پروتکل حذف رباتها (REP) است، گروهی از استانداردهای وب که نحوه خزیدن رباتها در وب، دسترسی و فهرستبندی محتوا و ارائه آن محتوا به کاربران را تنظیم میکند.
REP همچنین شامل دستورالعملهایی مانند رباتهای متا و همچنین دستورالعملهای صفحه، زیر دایرکتوری یا سراسر سایت برای نحوه برخورد موتورهای جستجو با لینکها (مانند «دنبالکردن» یا دنبال نکردن «nofollow») است.
همچنین با داشتن یک فایل robots.txt به مدیریت فعالیتهای این خزندههای وب کمک میکنید تا بر سرور وب میزبان وبسایت مالیات اضافه نکنند، یا صفحاتی که برای نمایش عمومی نیستند فهرستبندی نکنند.
عامل کاربر چیست؟
هنگامی که یک برنامه، اتصال به یک وب سرور را آغاز میکند (خواه یک ربات باشد یا یک مرورگر وب استاندارد)، اطلاعات اولیه هویت خود را از طریق یک هدر HTTP به نام “user-agent” ارائه میدهد که منظور همان عامل کاربر است.

موتورهای جستجو دو کار اصلی دارند:
1- خزیدن در وب برای کشف محتوا
2- ایندکس کردن آن محتوا بهطوریکه بتوان آن را برای جستجوگرانی که به دنبال اطلاعات هستند ارائه کرد.
فایل روبوتس فقط یک فایل متنی بدون کد نشانهگذاری HTML است (ازاینرو پسوند txt. میگیرد).
فایل روبوت سایت مانند هر فایل دیگری در وبسایت بر روی وب سرور میزبانی میشود.
در واقع، فایل robots.txt برای هر وبسایت معینی معمولاً با تایپ URL کامل برای صفحه اصلی و سپس اضافهکردن /robots.txt مانند https://www.webjavan.com/robots.txt قابل مشاهده است.
این فایل به جای دیگری در سایت پیوند داده نشده است، بنابراین کاربران به احتمال زیاد به آن برخورد نمی کنند، اما اکثر رباتهای خزنده وب قبل از خزیدن سایت، به دنبال این فایل میگردند.
درحالیکه یک فایل روبوت به خزندهها دستورالعملهایی را ارائه میدهد تا راهنمای آنها باشد و این خاصیت یک ربات خوب است!
یک ربات بد یا فایل robots.txt را نادیده میگیرد یا آن را پردازش میکند تا صفحات وب ممنوعه را پیدا کند.
برای خزیدن در سایتها، موتورهای جستجو پیوندها را دنبال میکنند تا از یک سایت به سایت دیگر بروند، در نهایت، در میان میلیاردها لینک و وبسایت خزیده میشوند. این رفتار خزیدن گاهی اوقات بهعنوان “عنکبوت” شناخته میشود.
اگر فایل robots.txt حاوی هیچ دستورالعملی نباشد، به صورت پیشفرض برای خزندهها اجازه برخی کنجکاوی در وبسایت را ارائه میدهد.
robots.txt به حروف کوچک و بزرگ حساس است: نام فایل باید “robots.txt” باشد (نه Robots.txt، robots.TXT یا غیره).
بیشتر ببینید : لیست قیمت تبلیغات اینستاگرام
robots.txt یک فایل متنی است که باید در ریشه سرور سایت قرار گیرد، بهعنوانمثال: https://webjavan.com/robots.txt.
ولی نمی توان آن را در یک زیر شاخه قرار داد. برای مثال:
در http://webjavan.com/pages/robots.txt این امکان وجود ندارد.
اما میتواند برای زیر دامنهها اعمال شود. برای مثال: http://website.webjavan.com/robots.txt
نام فایل robots.txt باید با حروف کوچک باشد (بدون Robots.txt یا ROBOTS.TXT).
مثال اول : User-agent: [user-agent name]
مثال دوم : Disallow: [URL string not to be crawled]
نکته : [رشته URL نباید خزیده شود]
مثالهای ذکر شده با هم بهعنوان یک فایل robots.txt کامل در نظر گرفته میشوند؛ اگرچه یک فایل ربات میتواند حاوی چندین خط از عوامل و دستورالعملهای کاربر باشد (بهعنوانمثال، غیرمجاز، اجازه، تأخیر خزیدن و غیره).
در فایل روبوتکست، هر مجموعه از دستورالعملهای عامل کاربر بهعنوان مجموعهای مجزا ظاهر میشود که با یک شکست خط از هم جدا شدهاند:
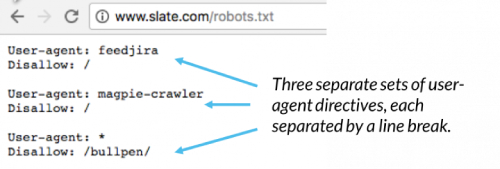
در یک فایل robots.txt با چندین دستورالعمل کاربر، هر قانون غیرمجاز یا مجاز فقط برای عاملهای کاربر مشخص شده در آن مجموعه جدا شده از خط خاص اعمال میشود.
اگر فایل حاوی قاعدهای باشد که برای بیش از یک کاربر عامل اعمال میشود، خزنده فقط به خاصترین گروه دستورالعملها توجه میکند.

عامل کاربر: * غیرمجاز: / (User-agent: * Disallow)
استفاده از این نحو در فایل robots.txt به همه خزندههای وب میگوید که هیچ صفحهای را در www.webjavan.com از جمله صفحه اصلی، نخزند.
عامل کاربر: * : (User-agent: *)
استفاده از این مدل دستور در فایل robots.txt به خزندههای وب میگوید که تمام صفحات www.webjavan.com از جمله صفحه اصلی را بخزند.
عامل کاربر: ربات گوگل (Googlebot) غیرمجاز: /برای مثال: زیر پوشه … /
(User-agent: Googlebot Disallow: /example-subfolder/)
این کار فقط به خزنده گوگل میگوید که هیچ صفحهای را که حاوی رشته URL www.webjavan.com/example-subfolder/ است، نخزد.
عامل کاربر: ربات بینگ (Bingbot) غیرمجاز: /برای مثال: زیرپوشه … / مسدود بشود از صفحه اچ تی ام ال (html)
(User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html)
این کار فقط به خزنده بینگ (نام عامل کاربر Bing) میگوید که از خزیدن صفحه خاص در www.webjavan.com/example-subfolder/blocked-page.html اجتناب کند.
برخی از عوامل کاربر (رباتها) ممکن است فایل robots.txt شما را نادیده بگیرند. این امر بهویژه در مورد خزندههای بد مانند رباتهای بدافزار یا خراش دهنده آدرس ایمیل رایج است.
فایل /robots.txt به صورت عمومی در دسترس است: فقط کافیست /robots.txt را به انتهای هر دامنه ریشهای اضافه کنید تا دستورالعملهای آن وبسایت را ببینید.
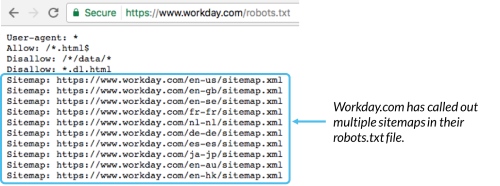
وقتی صحبت از URLهای واقعی برای مسدودکردن یا مجاز شدن میشود، فایلهای robots.txt میتوانند نسبتاً پیچیده شوند زیرا امکان استفاده از تطبیق الگو را برای پوشش طیف وسیعی از گزینههای URL ممکن میدهند.
گوگل و بینگ هر دو از دو عبارت منظم استفاده میکنند که میتوانند برای شناسایی صفحات یا زیر پوشههایی که یک SEO میخواهد حذف شوند، استفاده میکنند. این دو کاراکتر ستاره (*) و علامت دلار ($) هستند.
ستاره (*) یک علامت عام است که هر دنبالهای از کاراکترها را نشان میدهد.
علامت ($) با انتهای URL مطابقت دارد.
پروتکل نقشه سایت به رباتها کمک میکند تا بدانند چه چیزی را در خزیدن خود در یک وبسایت قرار دهند.
برای مثال نقشه سایت یک فایل XML است.
این یک لیست قابل خواندن ماشینی از تمام صفحات یک وبسایت است. از طریق پروتکل Sitemaps، پیوندهای این نقشههای سایت را میتوان در فایل robots.txt قرار داد.
قالب این است: “Sitemaps:” و سپس آدرس وب فایل XML میباشد. میتوانید چندین نمونه را در فایل Cloudflare robots.txt در بالا مشاهده کنید.
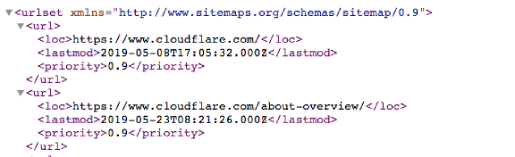
نقشههای سایت، رباتهای خزنده را مجبور نمیکنند تا صفحات وب را متفاوت اولویتبندی کنند.
ویژگی ارسال ابزار آزمایش robots.txt به شما این امکان را میدهد که گوگل را سریعتر خزیده و فایل robots.txt جدید را برای سایت خود فهرست کنید. با دنبالکردن مراحل زیر، گوگل را از تغییرات فایل robots.txt خود مطلع کنید:
1- روی Submit در گوشه سمت راست پایین ویرایشگر فایل robots.txt کلیک کنید. با این کار کادر محاورهای “ارسال” باز میشود.
2- کد robots.txt اصلاح شده خود را از صفحه ابزار تست Robots.txt با کلیک بر روی دکمه آپلود در کادر محاورهای آپلود کنید.
3- فایل robots.txt جدید خود را بهعنوان یک فایل متنی به نام فایل robots.txt به ریشه دامنه خود اضافه کنید. URL فایل robots.txt شما باید به این شکل: /robots.txt باشد.
4- برای تأیید اینکه فایل robots.txt آنلاین نسخهای است که میخواهید گوگل آن را بخزد، روی تأیید نسخه آنلاین کلیک کنید.
5- روی ارسال نسخه آنلاین کلیک کنید تا به Google اطلاع دهید که فایل robots.txt شما تغییر یافته است و از Google بخواهید آن را بخزد.
6- با بازخوانی صفحه در مرورگر خود برای بهروزرسانی ویرایشگر ابزار و مشاهده آنلاین کد فایل robots.txt، بررسی کنید که آخرین نسخه شما با موفقیت خزیده شده است.
هنگامی که صفحه بهروزرسانی شد، میتوانید روی منوی کشویی بالای ویرایشگر متن نیز کلیک کنید تا مُهر زمانی نمایش داده شود که نشاندهنده زمانی است که گوگل برای اولینبار آخرین نسخه فایل robots.txt شما را دیده است.
موتورهای جستجو و سایر رباتهای خزنده وب هر زمان که به سایتی مراجعه میکنند، میدانند که باید به دنبال فایل robots.txt بگردند. اما، آنها فقط آن فایل را در یک مکان خاص جستجو میکنند: در دایرکتوری اصلی (معمولاً دامنه اصلی یا صفحه اصلی شما).
اگر یک عامل کاربر از www.webjavan.com/robots.txt بازدید کند و فایل رباتی را در آنجا پیدا نکند، فرض میکند که سایت فایلی ندارد و به خزیدن همه چیز در صفحه (و شاید حتی در کل سایت) ادامه میدهد.
حتی اگر صفحه robots.txt مثلاً در webjavan.com/index/robots.txt یا www.webjavan.com/homepage/robots.txt وجود داشته باشد، توسط عوامل کاربر کشف نمیشود و در نتیجه سایت تحت درمان قرار میگیرد. انگار اصلاً فایل رباتی نداشتهاید.
فایلهای Robots.txt دسترسی خزنده به ناحیه های خاصی از سایت شما را کنترل میکنند. درحالیکه اگر شما به طور تصادفی Googlebot را از خزیدن در کل سایت خود منع کنید، میتواند بسیار خطرناک باشد، برخی موقعیت ها وجود دارد که در آن فایل robots.txt میتواند بسیار مفید باشد.
– جلوگیری از ظاهرشدن محتوای تکراری در SERP (توجه داشته باشید که متا رباتها اغلب انتخاب بهتری برای این کار هستند).
– خصوصی نگهداشتن بخشهای کامل یک وبسایت (بهعنوانمثال، سایت مرحلهبندی تیم مهندسی وب جوان).
– جلوگیری از نمایش صفحات نتایج جستجوی داخلی در SERP عمومی
– تعیین مکان نقشه(های) سایت
– جلوگیری از ایندکس کردن فایلهای خاص در وبسایت شما (تصاویر، PDF و غیره) توسط موتورهای جستجو.
– تعیین تأخیر خزیدن بهمنظور جلوگیری از بارگیری بیش از حد سرورهای شما هنگام بارگیری همزمان چند قطعه محتوا توسط خزندهها.
دقت داشته باشید که اگر هیچ ناحیهای در سایت شما وجود ندارد که بخواهید دسترسی عامل کاربر به آن را کنترل کنید، ممکن است اصلاً به فایل robots.txt نیاز نداشته باشید.
درکل robots.txt به شما این امکان را میدهد که دسترسی رباتها به بخشهایی از وبسایت خود را ممنوع کنید، بهخصوص اگر قسمتی از صفحه شما خصوصی باشد یا اگر محتوا برای موتورهای جستجو ضروری نباشد.
بنابراین، robots.txt یک ابزار ضروری برای کنترل نمایهسازی صفحات شما است.
بیشتر ببینید : طراحی سایت فروشگاهی
فایل روبوتکست، یک فایل و یک پل ارتباطی بین رباتهای گوگل و وب سایت ما است، با استفاده از دستورالعمل هایی که در فایل ربات مینویسیم به رباتهای گوگل میفهمانیم که به کدام قسمت سایت ما بخزند و کدام مناطق ممنوعه است.
شما با استفاده از دستورالعمل های کاربر عامل همانند User-Agent: * و یا سایر کدها، میتوانید به رباتها وظایفی را شرح دهید.








{kind=link}